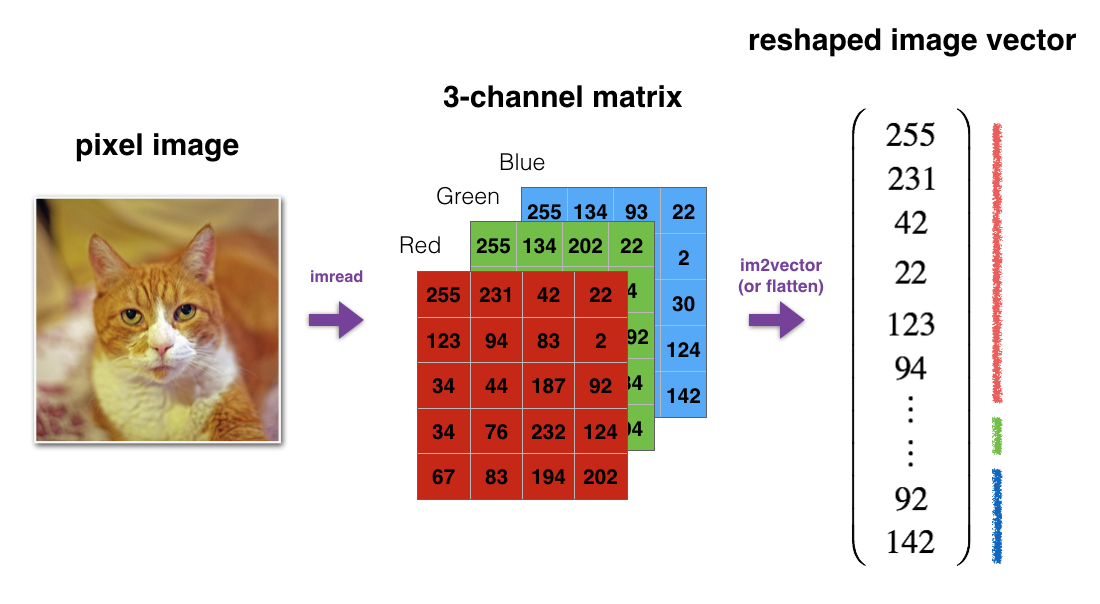
1. numpy로 기본 함수 만들기 ¶¶
Numpy는 Python의 과학 컴퓨팅을 위한 기본 패키지입니다. 대규모 커뮤니티 (www.numpy.org)에서 관리합니다. 이 연습에서는 np.exp, np.log 및 np.reshape 와 같은 몇 가지 주요 numpy 함수를 학습합니다. 향후 과제을 위해 이러한 함수를 사용하는 방법을 알아야 합니다.
1.1 시그모이드 함수, np.exp( )¶
np.exp( )를 사용하기 전에 math.exp( )를 사용하여 시그모이드 함수를 구현합니다. 그러면 np.exp( )가 math.exp( )보다 더 나은 이유를 알 수 있습니다.
(2) 연습 : 실수 $x$의 시그모이드를 반환하는 함수를 만듭니다. 지수 함수에는 math.exp(x)를 사용하십시오.
참고 : $sigmoid(x) = \frac{1}{1 + e^{-x}} $는 때때로 로지스틱 함수라고도 합니다. 머신러닝(로지스틱 회귀)뿐 아니라 딥 러닝에서도 사용되는 비선형 함수입니다.
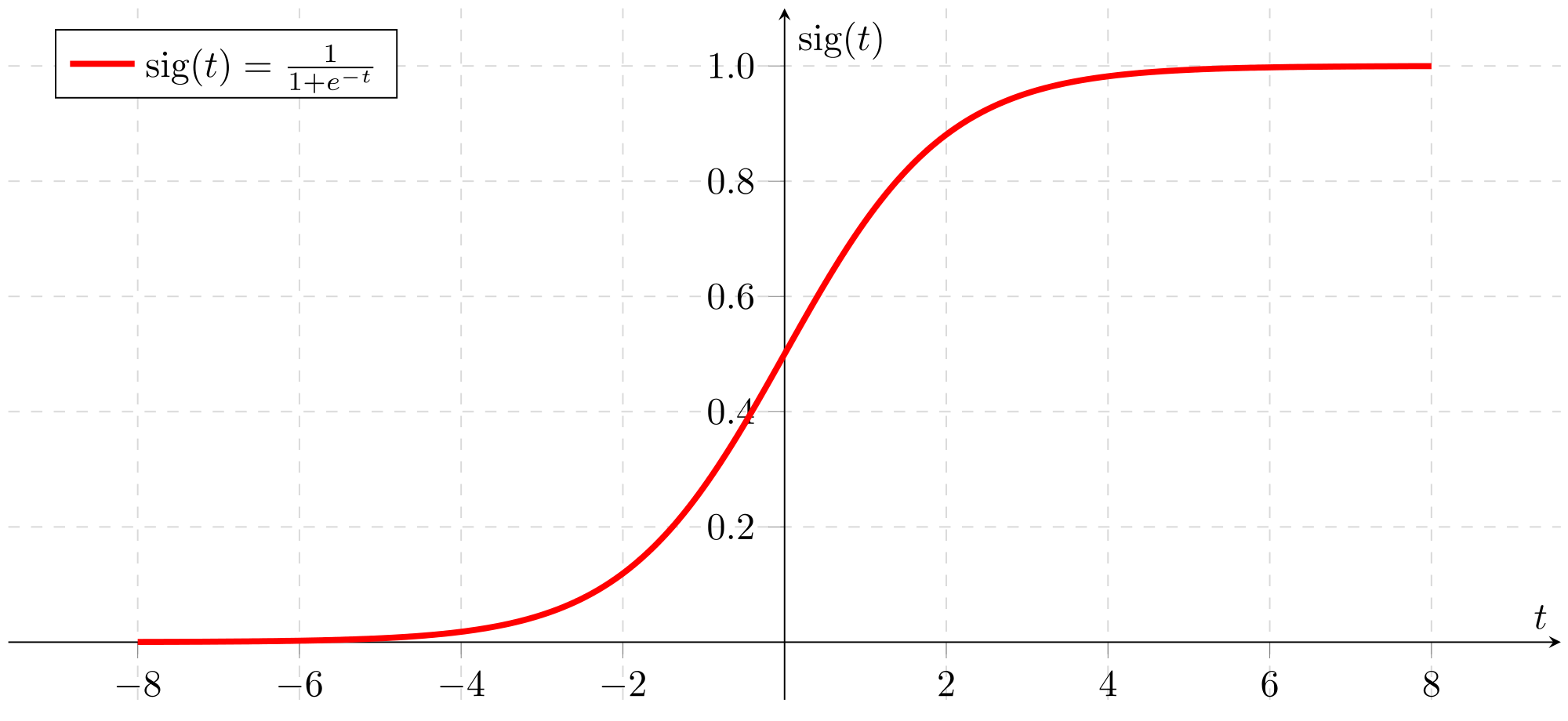
특정 패키지에 속하는 함수를 참조하려면 package_name.function( )을 사용하여 호출할 수 있습니다. 아래 코드를 실행하여 math.exp( )를 사용한 예제를 확인하십시오.